前言
头篇刚分析完Picasso,我兴致勃勃的打起了Fresco的主意,看了将近40分钟之后,我问了我自己三个问题。
1 2 3 |
1.为什么要折磨自己? 2.这是给人看的代码吗? 3.一个图片加载框架有必要这样复杂吗? |
冷静了20分钟后,我也回答了我自己
1 2 3 |
1.为了成为牛逼的人 2.这确实不是给普通人看的代码,是给厉害的人看的代码 3.只要是存在的就一定有必要,只是目前你还看不懂 |
所以,入坑吧
1.结构分析
fresco 的结构核心大致分为DraweeView,DraweeController,ImagePipeline,也就是网上流行的说法MVC。
1.1 DraweeView
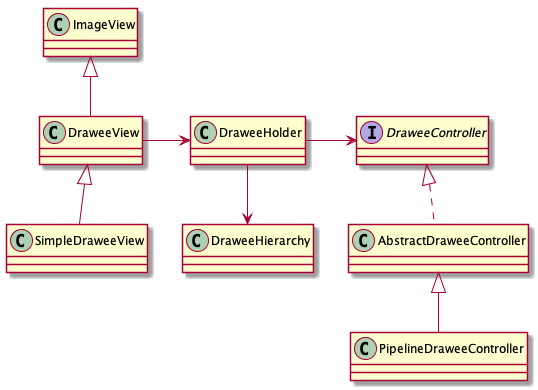
fresco中DraweeView属于目标,一个DraweeView会绑定一个DraweeHolder,DraweeHolder属于一个关联中枢 其中DrawHodler中绑定了一个层级Drawable,这个Drawable会事先设置到DraweeView上,在资源获取完成之后 就会重新渲染。
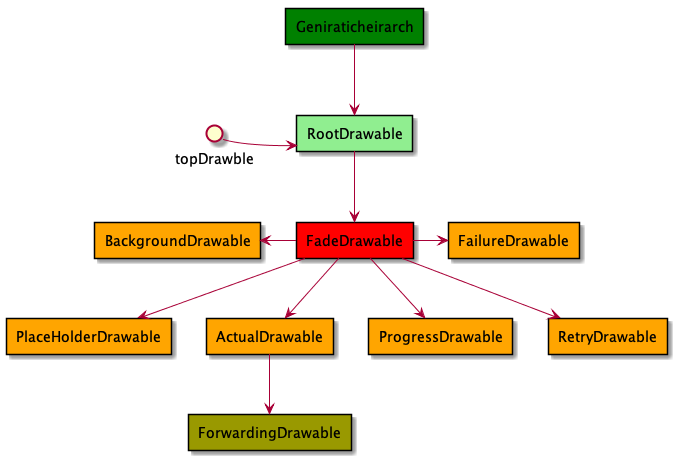
DraweeHolder绑定的层级Drawble其实就是DraweeHierarchy,如上图表示,这些层级Drawble实际上是为了表示 不同加载状态的,其中的ActualDrawable就是真正的目标Drawable,其他的都是辅助。
1.2 DraweeController

DraweeHolder关联的DraweeController属于一个调度中枢,启用一个生产消费模式和一个观察者模式,生产者这边 主要是ImagePipeline来负责生产数据来源,最后会将处理结果交给DataSubscribler来通知目标。这个目标就是上述hierarchy中的ActualDrawable
1.3 ImagePipeline
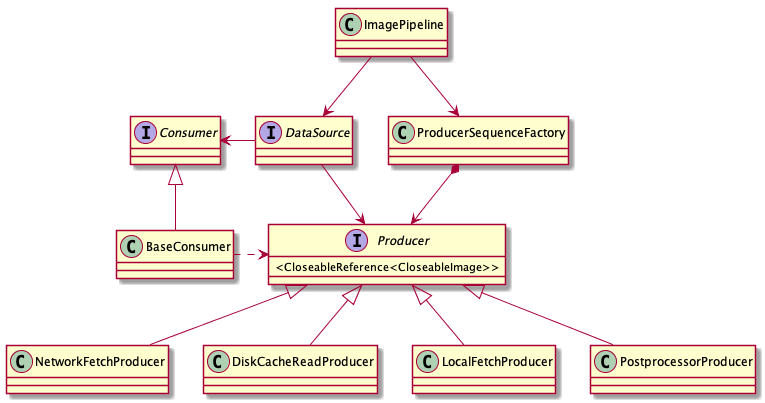
ImagePipeline这边负责根据缓存策略和url方式来向不同的Producer来获取资源。ImagePipeline会将具体的任务委托到 Producer来处理,Producer会将处理后的结果返回给相应的绑定的Consumer来返回给DataSubscribler。
调度
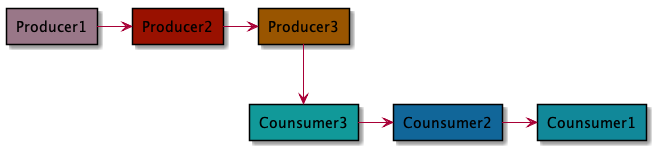
Fresco的源码运用了较多的设计模式,Builder,Factory,观察者等模式,将复杂的业务抽离封装。他的获取图片资源的方式也跟 普通的线性调用不一样,他是采用层层包裹Producer,每层Producer按照需要都会注册相应的Consumer,这样整个数据流向就跟上图 一样,Producer先调用的,绑定的Consumer就最后调用。
每层Producer会根据需要选择是否调用下一层Producer,这样实现逻辑的分发。比如某一层Producer缓存命中,就不会继续去网络请求。
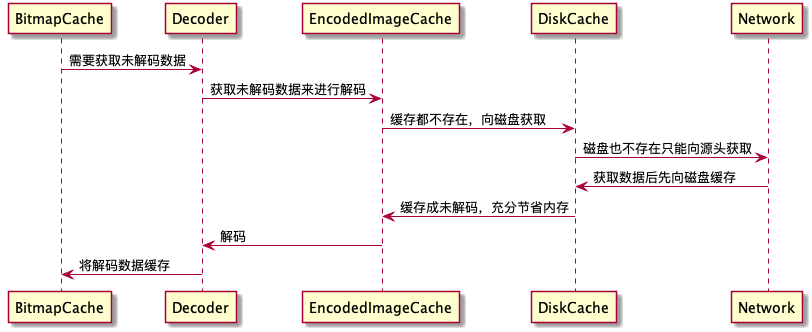
上图所示,一个完整的网络图片请求大致会经过这个几个阶段,两级内存缓存和一级磁盘缓存,比较特殊的就是这个两级内存缓存, 一个是未解码缓存,一个是已解码缓存,这样Fresco就能兼顾内存大小和获取速度两个因素。
缓存
内存缓存
结构分析
关于内存缓存,fresco的处理比较复杂,这块我们顺着上图一个一个来解说。
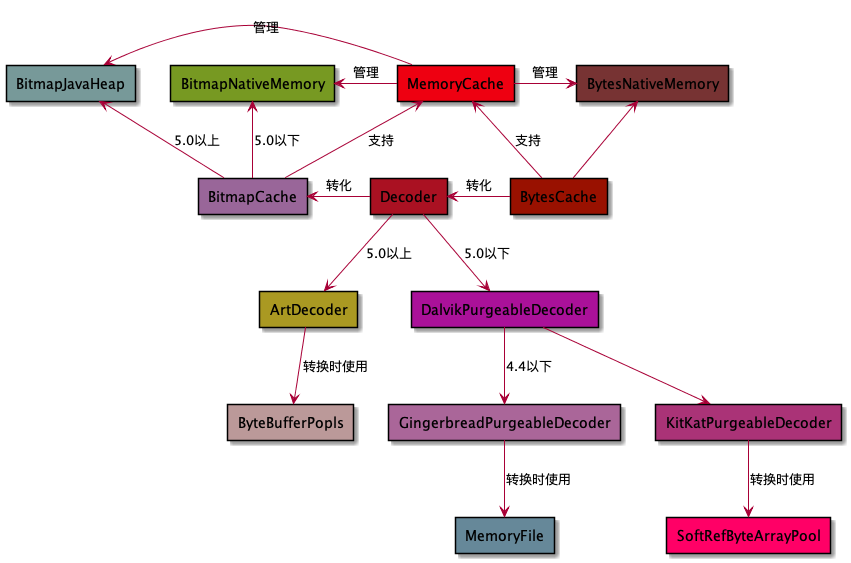
首先是关于内存的分类,fresco将内存缓存设置成两级,一级是Bitmap缓存,一级是Byte数组缓存,bitmap本身相对于未解码的字节体积 是巨大的,这里fresco所以这样进行了细化处理。
解码器
再者,既然有编码数据byte数组,那么必然诞生了一个解码器,也就是图中的Decoder,这个Decoder也被fresco进行了细化,因为在多线程 工作下,解码所需的临时缓存区也不能单纯的向Java堆中去获取,必须进行了很好的管理,不然必定引起OOM。在这个细分问题上,fresco根据 版本特性细化出了三个解码器,就是图中的ArtDecoder,GingerbreadPurgeableDecoder,KitKatPurgeableDecoder
ArtDecoder属于5.0以上,5.0以上,Bitmap有个新特性就是可以挂载多个数据实体,也就是BitmapOption中的inBitmap中可以挂载一个 已经被使用的Bitmap,只要该Bitmap比目前需要的尺寸大就行了,同时需要给这个解码过程传入一个解码数据缓存数组,也就是给inTempStorage 赋值
|
|
其中byteBuffer就是从ByteBufferPopls去获取,这个数据池中保存了最大线程数个16k的数据块,来满足多线程的解码需求。 而bitmapToReuse来源就是图中BitmapJavaHeap中分配的。
GingerbreadPurgeableDecoder和KitKatPurgeableDecoder主要用于5.0以下的系统。KitKatPurgeableDecoder解码需要的缓存数据块 来源于SoftRefByteArrayPool,SoftRefByteArrayPool其实跟ArtDecoder所用的BitmapJavaHeap都是来源于JavaHeap,他们都是继承于 BasePool的。BasePool里面的包含的数据是根据从小到大来排列的,在获取时,只要找到一个比所需数据刚刚大的数据就直接返回,达到充分利用的目的。
GingerbreadPurgeableDecoder则利用了MemoryFile在开辟了一个匿名共享内存来作为缓存数据块,这样也规避了在4.4以下的应用内存不足的问题
Bitmap缓存
Bitmap缓存实际上是根据版本来划分的,在5.0以上用BitmapJavaHeap来分配,BitmapJavaHeap中每个Bitmap都能被重复使用,这个也是前文提到的 5.0以上的特性所提供的便利。
在5.0以下,则从Native层获取内存(涉及jni调用,暂时没有深入分析)
byte数组缓存
未解码的数据就由BytesCache来管理,BytesCache实际上也是直接从Native分配内存的,看到这一点时,我也有个疑问,为什么Bitmap缓存不直接从 Native中去分配,还要在JavaHeap中获得。感觉在这个问题上fresco的作者也是非常小心的,毕竟Bitmap的数据量比普通的字节数组要大的多,不能 肆无忌惮从其他地方获取,用BitmapJavaHeap来妥善管理是比较好的实现。
MemoryCache
内存缓存的中心组件MemoryCache,实际上并没有保存数据,真正的数据是保存在BitmapNativeMemory,BitmapJavaHeap,BytesNativeMemory这 三个地方的。MemoryCache所起的作用其实只是一个管理作用,怎么放入缓存,怎么取出缓存,怎么清理缓存是其真正的工作。
比较有意思的是MemoryCache中对于LinkedHashMap的使用跟Picasso的不太一样,Picasso是真正意义上的实现了Lru算法,而Fresco这边,每次真正 会被剔除的缓存数据其实是最旧的数据(也就是说,谁先进入,谁就先被剔除),具体就是LinkedHashMap使用了默认的构造方法
|
|
磁盘缓存
磁盘缓存没有什么特殊之处,只是在存储为文件时,并不是图片格式,而是以cnt为结尾的文件实体。
总结
Fresco的代码比较庞大,最大个感受就是作者充分的利用了Native内存来解决应用特有的OOM问题,但是在这块,作者也是非常的小心,对于内存的 管理都是做了很多深入的优化实现。这次其实只是分析了一个大概,对于一些细节上并没有做过多的深究,以后有时间还会继续深入分析,毕竟Fresco我感觉 真的可以作为android上一个内存管理的典范。
感谢
MemoryFile 文件