Vsync
测绘需要经过cpu的运算,gpu的分配,硬件的渲染,因为在人的眼睛感官中,每秒大于等于60帧画面时,我们就不会对于画面产生卡顿的感觉,这样换算下来,也就是大概16ms需要 更新一帧,在Android 系统中,硬件会发出类似的频率信号,然后经过软件层面的分发,最终交予绘制过程去调度,这个就是android上的Vsync的信号流程。
每16ms一个信号来时,就要开始测绘,具体就是Java层开始执行measure layout draw 三大流程,三大流程之后,gpu开始工作,最后硬件完成渲染。整个过程理想状态下是应该 在16ms内完成,如果超时,是无法进行下一个周期流程的,这里android 采用了双缓存,所谓双缓存,是因为一次测绘流程需要一个缓存区域,完成渲染后之后,才能释放这个缓存 区域,如果不能在16ms内完成流程,就启动第二个缓存区域来开启下一个流程,这样两个缓存区域搭配使用,能够避免很多卡顿闪屏的情况。当然很多时候,如果两个缓存区域也无法 满足使用,就会采用三缓存策略,具体原理跟双缓存的原理一样。
至于提到不能在16ms内完成的情况,一般来说都是我们在设计布局时的不合理,导致了measure layout draw三大流程过慢,所以我们需要合理的设计布局,避免层级过深,避免冗余布局。
Choreographer
Choreographer是Java层对于Vsync信号的一个中介者,拥有可以发起请求Vsync信号和响应Vsync信号的功能。

图中显示了一次完整的信号请求和回调,这里我们分为两个步骤来解说,步骤1步骤2为Vsync请求,步骤3和步骤4为Vsync回调
Vsync 请求
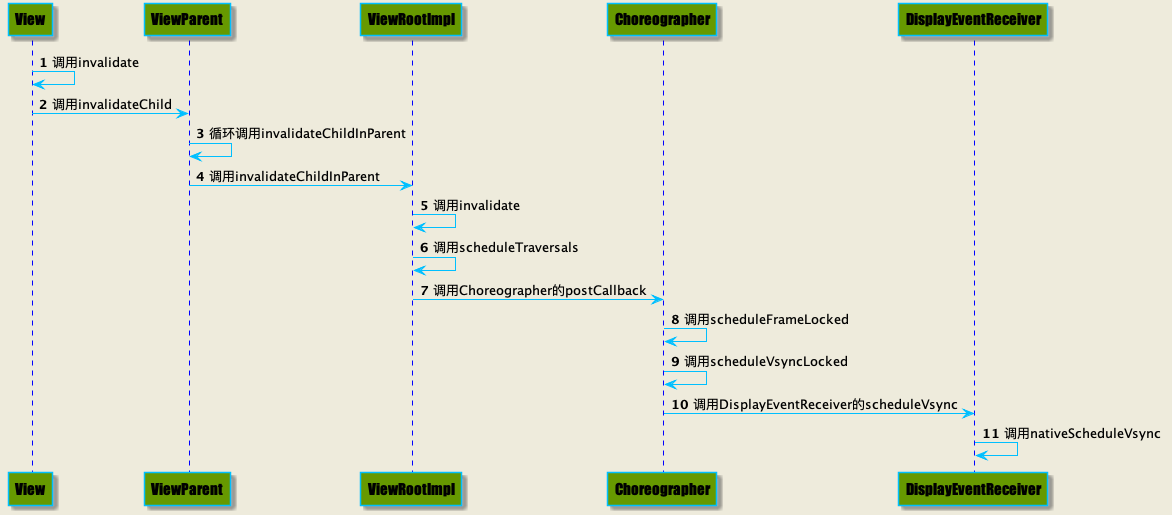
我们在平时需要更新视图布局时会使用View的invalidate方法,这个方法会触发View本身绑定的ViewParent的invalidateChild方法, ViewParent是一个接口有两个实现者,一个是ViewGroup,一个就是ViewRootImpl,我们看看ViewGroup的具体实现
|
|
parent.invalidateChildInParent会将parent的parent返回,这样就不断向上调用,最终调用了ViewRootImpl。 ViewRootImpl会将任务派发给Choreographer,Choreographer继续去请求Vsync,其实这里有个判断
|
|
USE_VSYNC为系统配置,如果配置为false是不会走Vsync的信号协调的,会直接渲染(MSG_DO_FRAME信号表示进入三大流程) 如果走Vsync信号,最终在FrameDisplayEventReceiver会调用JNI进入native。
|
|
Vsync 回调
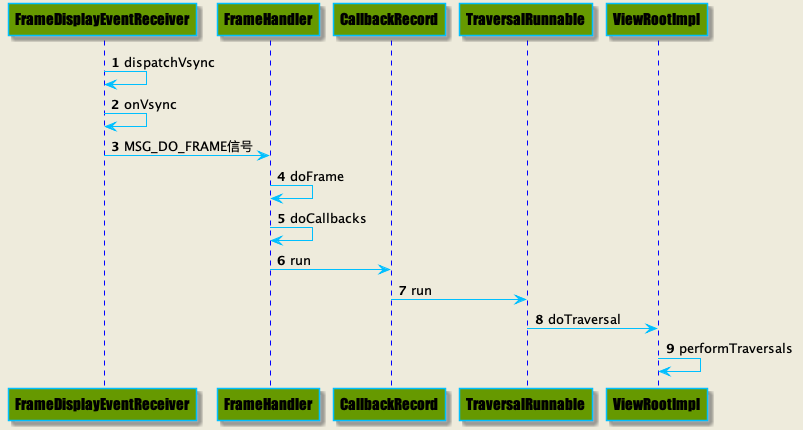
Vsync信号的回调还是会从FrameDisplayEventReceiver中回传来
|
|
在FrameHandler处理中会得到一个CallbackRecord,这个其实在Vsync请求时,存入的,到了doCallbacks方法时,会将存入的 Runnable 任务遍历执行,TraversalRunnable就是其中一个,TraversalRunnable中的任务就是ViewRootImpl中的方法
|
|
doTraversal会继续执行performTraversals方法,performTraversals方法里面包含了三大流程。
|
|
Traversal
Traversal的一种解释就是“树的遍历”,这很贴切布局的遍历过程。
Measure
测量是第一个流程,也是最重要的流程,View主要是确定自身的测量尺寸,ViewGroup需要在对子View进行遍历确定子View的尺寸之后,再确定自身的尺寸。

只要调用了setMeasuredDimension就算确定了测量尺寸。
每个View在测量是都会有从父布局传入两个个int类型的数据 MeasureSpec,分别用于width和height的测量使用,MeasureSpec的32位数据中高两位表示三种测量模式,低30位表示父布局传入参考尺寸。三种测量模式分别是
| mode | 含义 |
|---|---|
| EXACTLY | 尺寸明确,就是传入的尺寸 |
| AT_MOST | 尺寸不能大于传入尺寸 |
| UNSPECIFIED | 尺寸不做限制 |
在当前父布局传给子布局时会根据子布局的设定宽高来确定子布局的测量模式和参考尺寸。在上述流程图中的measureChild会经过这个计算过程,具体计算规则如下。
| child\parent | EXACTLY | AT_MOST | UNSPECIFIED |
|---|---|---|---|
| childSize | childSize | childSize | childSize |
| MATCH_PARENT | parentSize | parentSize | parentSize |
| WRAP_CONTENT | parentSize | parentSize | parentSize |
| child\parent | EXACTLY | AT_MOST | UNSPECIFIED |
|---|---|---|---|
| childSize | EXACTLY | EXACTLY | EXACTLY |
| MATCH_PARENT | EXACTLY | AT_MOST | UNSPECIFIED |
| WRAP_CONTENT | AT_MOST | AT_MOST | UNSPECIFIED |
图中可以知道,一般子布局指定了确定尺寸就会使用指定尺寸,所以需要特殊考虑的就是在MATCH_PARENT 和 WRAP_CONTENT两种宽高模式下的尺寸确定。 MATCH_PARENT的情况下,不管是测量大小还是测量模式都是直接使用父布局的。 WRAP_CONTENT的情况下,大小会使用父布局传入的,但是测量模式除了UNSPECIFIED,都是AT_MOST。
也就是说如果布局都是使用MATCH_PARENT或者WRAP_CONTENT这种不是很明确的方式来表示尺寸,最后可能导致使用WRAP_CONTENT却得到了MATCH_PARENT的效果
当然这个是针对没有经过再定义的View,像TextView再定义的View都有各自关于这种情况的处理,避免错误表达。
Layout
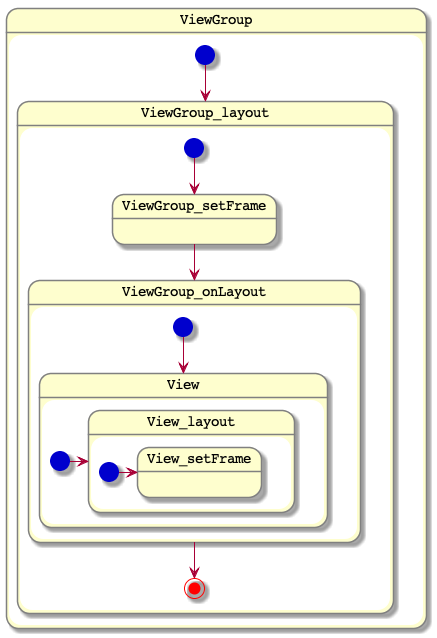
layout阶段主要是根据计算的测量尺寸来设定当前的view的坐标,在setFrame方法中,通过对mLeft,mTop,mRight,mBottom赋值来确定View的坐标和大小。
|
|
图中也会更新一个mRenderNode的坐标,RenderNode是用作硬件加速使用的,在后续绘制流程中使用。
getMeasuredWidth和getWidth
这里讨论一下,这个两个长度的区别,两者代码如下
|
|
mMeasuredWidth是在measure流程之后获得,而mRight和mLeft是在layout流程之后获得,mRight和mLeft依赖mMeasuredWidth,但是也可以我们在自定义时自动 设置。比如下面代码
|
|
所以如果是严格按照mMeasuredWidth的标准来设置mRight和mLeft的话,getMeasuredWidth和getWidth会得到一样的结果,否则结果不一样,并且getWidth的结果比getMeasuredWidth更准确。
Draw
在ViewRootImpl的draw方法中有个很重要的分界点
|
|
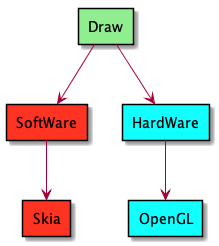
这个判断决定了Draw阶段是使用软件绘制还是硬件加速绘制。
软件绘制
|
|
软件部分很简单,Surface向SurfaceFlinger申请一块匿名共享内存内存分配,获得一个画布Canvas,这个Canvas其实是Skiacanvas,用于调用Skia库,进行图形绘制 在draw中通过递归操作子View绘制canvas,完成渲染。这个实际都是属于软件绘制,因为整个过程都要经过cpu完成,cpu对于图形渲染这种矩阵浮点操作本身不是很擅长,并且绘制过程一直处于主线程,不是最理想的绘制方式。
硬件加速
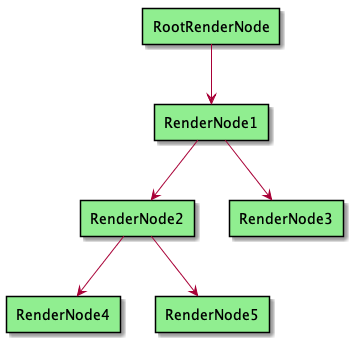
关于硬件绘制需要了解绘制主要是依赖的是RenderNode,每个View拥有一个RenderNode,每个RenderNode会产生一个DisplayListCanvas,DisplayListCanvas继承于Canvas,能够像普通的Canvas使用,也能绘制RenderNode,方法名为drawRenderNode。这样一个父RenderNode通过调用drawRenderNode可以将子View的RenderNode关联到父RenderNode,这样将View的绘制步骤都转换成一颗RenderNode 树。在native层RenderNode树的绘制过程会有专门的RenderThread来完成。
|
|
上述代码为硬件加速绘制部分,updateRootDisplayList完成根节点RenderNode的生成。
|
|
同时调用view的updateDisplayListIfDirty完成层View的RenderNode递归绘制和添加操作
|
|
不管是在dispatchDraw还是draw方法,都会调用到dispatchDraw方法。draw方法中完成本层View 内容的绘制,dispatchDraw完成下一层级View的绘制
|
|
到了draw(Canvas,ViewGroup , long )这个三个参数的draw方法(前面的draw方法是单参数),就到了递归点,完成下下层RenderNode的添加。
单是从代码上看,软件绘制和硬件绘制的区别就是,软件绘制是整个绘制过程都是用一个Canvas从上到下传递,而硬件绘制是每一层生成一个Canvas(DisplayListCanvas) 绘制本层内容同时也绘制下一层的RenderNode。
总结
一次软件测绘分析,还是设计了大量方面的知识,我不仅了解了GPU,CPU绘制的区别,还要去看SurfaceFlinger的东西(虽然没什么进展)。还是那句话,虽然一吨棉花才能出一滴水,别人只看到了一滴水,但是你却能看到一吨棉花,下一次我还想挤一滴水的时候,就不需要再去找那么多的棉花了。共勉!!!